
Color-Based Hand Gesture Recognition on Android
This is my course project for CS290I(Mobile Imaging) in UCSB. The goal is to detect and recognize user-defined gestures using the camera of Android phone. A demo Android app that lets the user launch other applications using gestures is developed to show the real time performance.
Overview
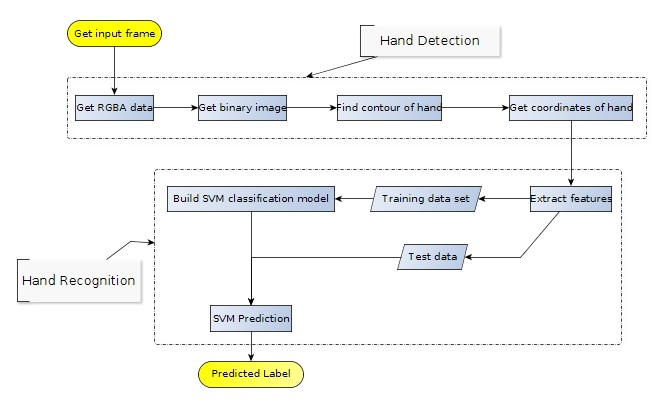 Architecture for Hand Gesture Recognition on Android
Architecture for Hand Gesture Recognition on AndroidPresampling and Hand Segmentation
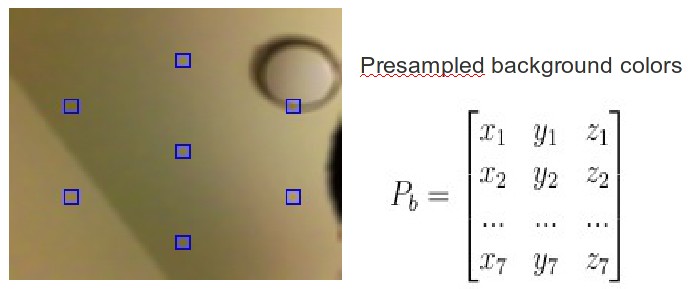
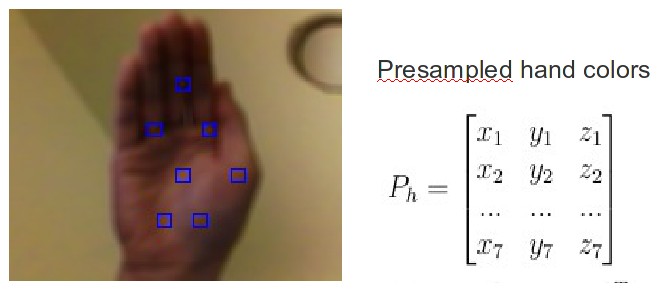
The app starts with two pre-sampling steps, which collect colors of background and the user’s hand using 7 small squares displayed on the screen. These color data are used to compute the thresholds to get the binary image from the input RGBA data. For simplicity, adaptive method was not used to find the best threshold. Instead, the user is asked to put his hand close to the screen to cover the 7 squares so that the program can get the color data of the hand. Note that the number of squares is just an empirical value and it can be other values. After the 7 color data for the hand are obtained ,7 upper and lower boundaries for the hand area are computed, which can be represented as a 6 dimensional vector. The bounding vector is determined by the developer and could not be changed. Therefore, the performance of the segmentation actually depends on the choice of the bounding vector. To better understand the influence of each element of the vector on the segmentation performance, the original RGB color space is converted to many other color spaces like HSV, YCrCb, CIE L*a*b*. Since for the same hand, the color usually varies most on the lighting dimension and smaller on hue and other color dimensions, the desirable color space should be able to separate them. After some experiments the three color spaces listed are all found to perform quite well, but it is easier to find the best bounding vector by using LAB space. Therefore the LAB color space is used.
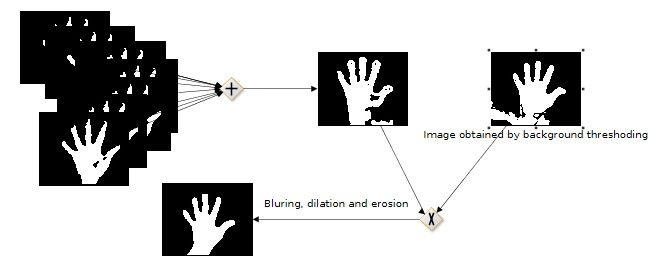
After the boundaries for each of the 7 color data are obtained, 7 binary images of the hand can be computed, which are then summed up using logical operation “or”. The same thing are done on the background color, producing another binary image. The logical operation “and” is then done on the two binary images and the result is blurred, dilated and eroded to eliminate noises, and the final binary image is obtained, as is shown in the above picture.
Feature Extraction
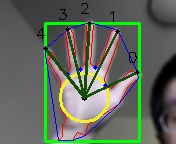 Illustration of the elements needed to calculate features. The green box represents the bounding box of the hand. The blue line represents the convex hull. The red line is the contour of the hand. The green dots between the fingers are defect points. The yellow circle is the inscribed circle and the black dot is the center of the circle, which is treated as the center of the palm. The dark green lines are finger vectors, and the order is indicted by the numbers
Illustration of the elements needed to calculate features. The green box represents the bounding box of the hand. The blue line represents the convex hull. The red line is the contour of the hand. The green dots between the fingers are defect points. The yellow circle is the inscribed circle and the black dot is the center of the circle, which is treated as the center of the palm. The dark green lines are finger vectors, and the order is indicted by the numbersThe features used to represent the hand are low-level features, which essentially are the finger vectors. To compute them, it is necessary to find out the locations of the palm center and the fingertips. Some of the OpenCV functions can directly return the contour and convex hull points of the hand from a binary image containing the segmented hand. Using these coordinates and the bounding box, the center and radius of the inscribed circle of the contour can be computed. This part is quite computationally expensive and is implemented in native C++ code.
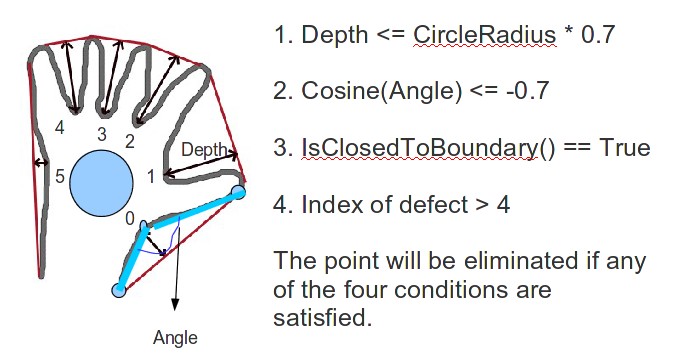
The locations of the fingertips are computed using the defect points. To do so, the redundant defect points are eliminated by checking constraints on the depth and angle of the defect points and so on, as is shown in the above picture. Next the defect points left are reordered and the finger tips are obtained from the returned coordinates of OpenCV functions. Finally the finger vectors are computed and divided by the radius of inscribe circle to get the final feature vector: $$X = [x_0 / r, y_0 / r, x_1 / r, y_1/r … x_4/r, y_4/r] $$.
Training Set

Currently 19 gestures have been collected to constitute the initial data set, as is shown in above figure. Note that although the extracted feature vector is invariant to different size of hand, it is variant to different orientations since gestures of different orientations are treated as different gestures. Also it can be seen from above figure that the “gesture” labeled as 0 is actually not a gesture. The label 0 is reserved to represent anything whose features are not detected. It can be counted as representing a negative example. It also reveals one of the limitations that the “fist” gesture can not be recognized.
The user can add whatever gestures they like to the initial data set or build another one using the application. The training process can be conducted in any conditions as long as the hand can be well detected. Due to time constraint, very few number of frames are collected for each gesture(Only 10 frames). Multi-class SVM is used to build the training model and make predictions.
Results and Analysis
To show the results, several tests were conducted in different lighting conditions and different backgrounds. For each gesture, 3 frames were captured together with the predicted labels shown as the red numbers in the photos. Three frames are far less than enough to prove the accuracy. However according to observation, the final recognition result highly depends on the detection result. In other words, if the hand is well-detected, which means the extracted feature vector correctly represents the hand gesture, then the hand can be classified into the right category with high probability. Therefore what really matters is actually the performance of hand detection rather than that of hand recognition. The performance of hand detection can be seen from the pictures captured, which display elements like the contour and finger vectors. Three frames are enough to see if these elements are correct and if they are stable or not.
 Results in Scenario 1
Results in Scenario 1 Results in Scenario 2
Results in Scenario 2 Results in Scenario 3
Results in Scenario 3The app was tested in three scenarios and the results are shown in above figures. It can be seen that the app worked quite well in Scenario 1 and Scenario 3: all the predicted labels are correct and most of the gestures are detected correctly and quite stable, except that there is one gesture not detected(Random error). And the main reason for the success is that there are sharp contrast in color between the background and the hand. Whether the background is cluttered or not does not matter, only the color matters.
In Scenario 2 some of the gestures are not well-detected. The main cause for this is that the yellow color in the background kind of interfere the extraction of contour of the hand. Also the auto adjustment of the camera becomes stronger in this scenario which is probably because of the light.
In summary, with the help of presampled colors, the app can detect and recognize the hand quite well and stable in most of the lighting conditions and backgrounds, as long as the contrast of the background and the hand is not too poor. However the constraint is that they must keep the same once the presample processes finish. And that means both of the hand and the phone should not move too much, in order to avoid the change of the colors.
Demo
Summary
Potential Improvements
- Build statistical model for the color of background and hand instead of simple sampling and summing.
- Use adaptive thresholding to get the final binary image.
- Add elimination process of skin-like parts like wrist, forearm and face.
- Add feature representation for the “fist” gesture.
- Make prediction according to probability, rather than directly output the prediction frame by frame.
Limitations
Two most evident drawbacks mentioned before are influences of change in background colors and lighting conditions. One thing I found is that the camera on the phone has auto-adjustment like auto-exposure and auto white balancing which change the color of the hand and background as the view or position of the hand changes. This makes color-based methods not desirable to be used on mobile phones. The only solution is either finding ways to disable the auto adjustment, which I think is not possible on most of the devices, or abandoning the methods and instead use hand detection methods based on texture-like features together with some machine learning methods.
In addition, since low-level features are used to represent the gesture, some gestures can not be represented. Also it is hard to eliminate false-positives.
Acknowledgments
- The idea of presampling is from Simen Andresen’s blog
- Used LibSVM on Android implemented by Kun Li. link
- Used aFileChooser library to implement the file chooser.
- To implement mapping human gestures to Android apps, this article is quite helpful.
